The value of computational abstractions to non-expert end-user programmers is contentious. We study reactions to the lambda function in Microsoft Excel, which enables users to define their own functions using the spreadsheet formula language, through a thematic analysis of nearly 2,700 comments posted on the Reddit, Hacker News, YouTube, and Microsoft Tech Community online forums. We find that computational abstractions are viewed both as helpful and harmful, that users encounter learning and understanding barriers to applying them, and that there are deficiencies and opportunities in tooling such as in formula editing, versioning, reuse and sharing. We find that the introduction of lambda prompts new debate around whether spreadsheets are code, whether writing formulas can be considered programming, and whether spreadsheet users identify themselves as programmers.
Index terms — human-computer interaction, content analysis, end-user software engineering, functional programming
In December 2020, the lambda function was made available to Excel spreadsheet users, enabling them for the first time to create computational abstractions in spreadsheets, by defining new formula functions using the language of spreadsheet formulas alone [1]–[3].
This development is of interest to end-user programming research because, despite the status of the spreadsheet as the most widely-used programming environment, no commercially dominant spreadsheet package had implemented a language-native method for defining new functions; prior solutions relied on parallel scripting languages. Thus, the spreadsheet formula language remained an anomaly: the only widely-used programming language that did not support subroutine definition since the invention of subroutines in the 1940s [4], [5].
The limitations of the lack of a native computational abstraction in spreadsheets are well-documented (Section 2). In response, researchers have explored various abstraction mechanisms. The Forms in Forms/3 spreadsheets can be invoked as subroutines [6], and the design of sheet-defined functions [7], [8] demonstrates the integration of such abstractions into conventional spreadsheets. Nevertheless, such abstraction techniques were not implemented in commercial spreadsheets.
To deal with these limitations, users (with sufficient expertise) either resorted to using abstraction mechanisms offered using alternative programming paradigms (such as VBA macros in Excel, or Javascript custom functions in Google Sheets), or installing add-ins which introduced new language features, or alternating between spreadsheets and other programming languages [9]. Alternatively, some users developed workaround craft practices, such as the creation of templates for sections of grid that could be copied and pasted as self-contained computational abstractions [10], or built ‘megaformulas’: elaborate formulas constructed as individual parts but eventually ‘rolled up’ (nested) into a single cell for reuse.
Despite such evidence of abstractions in real-world spreadsheets, and the promise of lambda abstractions, it is unclear prima facie whether the lambda construct is a net gain for end-user programmers. For example, abstraction can make programming more powerful, and programs more concise and intelligible; on the other hand, they can make programs hard to understand, and poorly-considered application of abstractions can cause problems for downstream users of programs [11].
The introduction of such an abstraction capability to spreadsheets therefore raises two key questions:
What are the implications of computational abstractions for the end-user experience of spreadsheets?
What barriers do end-user programmers face when learning and using abstractions, and what strategies do they employ to overcome them?
To investigate these questions, we analysed discussions from online communities about the lambda function in Microsoft Excel (Section 3). While our analysis does not yet answer these questions in depth, our findings identify a broad set of phenomena, helping to map and scope further study.
We find several implications for the user experience of spreadsheets, such as the potential for abstraction to help as well as hinder comprehension, and the inadequacy of formula authoring and management tools; we find that users encounter several barriers to applying these abstractions and employ several strategies to address them; and we find that computational abstractions play a crucial role in the formation of user identities as programmers (Section 4). Thus, the lambda abstraction in spreadsheets can either be a powerful tool, as the golden bow of Apollo, or it can be an Achilles’ heel, weakening comprehension and community participation.
Lambda abstraction is a concept from the lambda calculus, introduced by Church as a foundation for mathematics [12], [13], and long considered a foundation for programming language concepts [14], [15]. Its implementation in Excel is via a formula function with the same name. To distinguish between the concept of lambda abstraction (as well as specific instances of function values, also known as lambdas), and the Excel function, we style the Excel function as lambda.
The lambda function takes as arguments a list of
parameters followed by a formula that may refer to those parameters. For
example, the following call creates a lambda that adds two numbers:
=lambda(x,y,x+y).
Placing such a call to lambda in a cell produces an
error, because in the Excel implementation, a function value cannot be
the result of a cell. Instead, the lambda can be directly invoked
following its creation: one can write =lambda(x,y,x+y)(2,3)
in a cell to yield the result 5.
To introduce a new user-defined function using a lambda
formula, a name can be assigned to the formula using the name manager.1 It can then be invoked via the name.
For example, one can assign the name AddNumbers to
=lambda(x,y,x+y) and invoke it, within a cell, as
=AddNumbers(2,3) to yield the result 5.
In the Cognitive Dimensions of Notations framework, Green and Petre define programming abstraction as the “grouping of elements to be treated as one entity” [16]. Data abstractions, such as arrays or tables, allow us to perceive and operate on a group of data as a single entity. Control or computational abstractions include conditionals, loops, and subroutines. lambda functions fall into the latter category.
In Cognitive Dimensions terms, a notation can be abstraction-hating, abstraction-tolerant and abstraction-hungry, based on whether it prohibits, permits, or mandates the creation of new abstractions by the programmer. lambda takes the spreadsheet formula language from being control abstraction-hating to a control abstraction-tolerant language.
Control abstractions are difficult for end-user programmers to reason about [17]. In notating multiple possible paths of execution, they resist direct manipulation interfaces [18]. Moreover, end-user programmers avoid developing control abstractions due to the attention investment required [19] and challenges when learning and creating them [16]. Programming by demonstration [20] and programming by example [21] aim to address these difficulties by bridging direct manipulation and control abstractions through inference.
Sheet-defined functions (SDFs) enable users to define their own computational abstraction using the spreadsheet formula language, much like lambda [7], [22]. However, SDFs differ from lambda in that the function body can be defined from a collection of cells, rather than a single formula.
A user study of SDFs found that while having a reusable abstraction was helpful, in many cases participants preferred to view the body of the function when invoked [8]. This contrasts with the hiding of the body and intermediate values that is inherent to the user experience of subroutines. In response, Gridlets, a non-hiding computational abstraction, has been proposed [10], [23] but not evaluated in an empirical study.
Another approach is to adopt practices from software development to spreadsheet development, for better long-term maintainability of spreadsheets. This is end-user software engineering [24], end-user development [25], or spreadsheet engineering [26]. ClassSheets [27] is an example of an engineering abstraction developed to manage spreadsheet complexity. End-user development research has also considered other engineering practices such as testing [28].
Complex models continue to be built using spreadsheets despite the lack of a native computational abstraction, resulting in challenges for correctness, maintenance and auditing [29]. In response, spreadsheet users have adopted various alternatives.
Expert users build abstractions using extensibility capabilities via a different language; examples are VBA macros in Microsoft Excel and JavaScript extensions in Google Sheets. Less expert users use third-party add-ins (e.g., Ablebits2, ASAP Utilities3) that provide utilities for common tasks to augment the built-in function library. Others delegate the development of complex spreadsheets to others with more (or different) expertise [30].
Users have also developed practices to manage the complexity of the spreadsheet logic, to abstract away details and to ease comprehension and maintenance. For example, the FAST standard4 for spreadsheet financial modeling recommends that formulas take no more than 24 seconds to explain, and to move intermediate calculations to separate sheets.
However, the adoption and effectiveness of such standards are limited. There is lack of awareness, and most spreadsheet users lack formal training. Moreover, users are not motivated to invest attention in learning and adopting these practices. End-user programmers are typically task-oriented, and good design is not a necessity for task completion [28].
A feature like lambda can be studied in many ways. An experiment with authoring or comprehension tasks can evince learning barriers or usability issues, while interviews with experienced users (if such a group could be recruited) can yield insights about lambda use and practices in users’ workflows.
Our motivation in this study is to observe the interaction of a broad range of end-user programmers with lambda. We were also interested in how perceptions of a new feature like lambda can develop and evolve in discussion amongst end-user programmers, something that is difficult to study in interview or experimental settings.
We therefore opted to study discussions of lambda in online communities. Communities such as Hacker News, Twitter and GitHub form a social ecosystem in which programmer relationships are formed and enacted [31] and studying them “can yield insights into qualitative research topics, with results comparable to and sometimes surpassing traditional qualitative research techniques” [32]. Barik et al. applied this method to investigate notions of play in programming [33], and we draw upon the method of that study.
To our knowledge, ours is the first systematic qualitative study of online communities in spreadsheet research.
One researcher compiled a list of potential sources, consisting of discussion threads matching the query “Excel Lambda” using the search functions built into Hacker News, Reddit, Microsoft Tech Communities and YouTube as of 20 January 2022. From the first three, we extracted discussion threads related to “Excel Lambda”; for YouTube, the search returns matches based on video titles and descriptions; the comments associated with these videos were taken to be the corresponding “threads”. Additional forum sources were inspected but not included because they contained too few (fewer than 100) relevant comments. After removing false positives in the threads by manual inspection, we gathered comments from the remaining threads using automated scripts.
Our final dataset, summarised in Table I, contained 361 distinct threads containing a total of 6999 comments authored by 3422 distinct user IDs. In total, this corpus contains 254,541 words of discourse either directly related to lambda or occurring in a thread about lambda, with an average of 36.37 words per comment. The data spanned the time period from 3 April 2008 through 1 February 2022. Even though a small proportion of these comments (6.9%) were written before the initial public release of lambda on December 3, 2020, we retained them in case any interesting observations had been made in users’ speculations about lambdas in spreadsheets.
| Words | Comments | Words per comment mean (sd) / median |
Threads | Unique user IDs | Date interval (first post - last post) |
|
| YouTube | 99878 | 4750 | 21.03 (30.83) / 13 | 45 | 2760 | 2020/08/13 - 2022/01/27 |
| Microsoft Tech Communities | 97363 | 1446 | 67.33 (74.61) / 44 | 182 | 214 | 2017/12/10 - 2022/02/01 |
| Hacker News | 39206 | 441 | 88.90 (130.46) / 47 | 109 | 307 | 2008/04/03 - 2022/01/08 |
| 18094 | 362 | 49.98 (95.22) / 24.5 | 25 | 141 | 2020/12/07 - 2022/01/21 | |
| Overall | 254541 | 6999 | 36.37 (62.27) / 18 | 361 | 3422 | 2008/04/03 - 2022/02/01 |
We used general thematic analysis with iterative coding and codebook development [34].
Initially, three researchers independently open-coded the same set of 400 comments (100 comments randomly sampled from each of the four sources). Together the researchers generated 94 proto-codes, which after discussion and negotiations led to an initial codebook of 29 codes. The three researchers then independently re-coded the same sample with the codebook. Manual inspection showed poor inter-rater agreement, consistent with initial open coding rounds in prior studies [35].
The three researchers then discussed coding disagreements and ambiguities and revised the codebook. They used the updated codebook to independently code a fresh random sample of 200 comments (50 from each source). The average inter-rater agreement in this round was 0.60 (Jaccard index). Disagreements were negotiated, and the codebook revised.
The final codebook, presented in Appendix A, consisted of 28 codes; 14 code definitions were updated and 2 were merged from the initial codebook following three rounds of negotiations between researchers.
Non-English comments could not be reliably interpreted by our English-speaking research team, and several comments were not relevant to Lambdas (e.g., “great video”). We coded these as irrelevant. These accounted for a sizeable fraction of the data (YouTube: 62%, Reddit: 54%, Hacker News: 48%, Microsoft Tech Community: 66%). Thus the findings presented in Section 4 draw from a pool of 2697 comments.
With this final codebook, the dataset was divided into four sets and one of four researchers (three being the coders from previous rounds, the fourth an observer during previous negotiations) coded each set. As standard validation practice [36], [37], a sample of at least 10% of code assignments made by each researcher was audited and re-coded by another; this had an acceptably high agreement of 0.86.
Finally, the researchers grouped codes into larger themes, discussed overall findings and selected representative quotes.
Our use of inter-rater agreement is primarily as a negotiation aid, since our findings do not hinge on frequency counts. In our analysis, codes are the process, not the product; our findings are organised into themes which were synthesized from these codes through the negotiation of expert researchers. In doing so, we align with McDonald et al.’s state-of-the-art analysis and guidelines for reliability in CSCW and HCI research [36]. To connect our findings to our codebook, direct references to codes are presented in bold.
lambda has several implications for the user experience of spreadsheets. It introduces a tension between abstraction and comprehension, and commenters propose an array of craft practices to cope. It also exposes limitations and opportunities in tooling. Commenters encounter barriers in learning and applying lambda, and employ a variety of strategies to deal with these barriers. Moreover, lambda leads commenters to critically evaluate their identity as programmers. Commenters contrast lambda with alternatives to situate it within the landscape of available tools. Finally, we observed differences in topics and concerns between the various communities we studied. These findings are now detailed in turn.
Abstraction is a double-edged sword and commenters seized upon this tension. While the benefits of lambda are described in terms of improved comprehension, debugging, and maintenance, in each of these areas commenters spotted the potential both for improvement and regression.
For example, commenters noted how lambda could both improve as well as impair comprehension, especially the readability of individual formulas.
[...] sometimes the excel formulas used are very long, convoluted, and hard to grok [...] Many cells often exist as calculation cells only, used for intermediate steps which leads to even more logic complexity. I’m excited to experiment with these to try and simplify some of the long, previously-deemed-necessary calculation methods. [HN176]
If I were to ever find someones sheet using Lambda, chances are that I don’t know what are his values refering to [...] [YT2021]
Similarly, commenters anticipated benefits as well as issues in debugging, testing, and auditing.
Wow this would make my reports easier to audit as the formula is only defined once. Plus easier [...] to read. [YT1264]
As a financial analyst, my primary worry is that including custom functions will make it hard for another analyst [...] to review my projections [...] without the ability to easily audit a LAMBDA, financial analysts will not adopt this feature. [M191]
Commenters postulated the implications of lambda for the maintenance of spreadsheets, in terms of not only the modularity, but also the obfuscation they enabled.
It should make spreadsheets smaller in size, easier to maintain, easier to audit and easier to use. [R49]
I really hope that’s true, but there’s lots of potential for the exact opposite as people cram entire programs into a single formula. [R77, responding to above.]
In general, commenters were divided on whether lambda functions were the Apollo’s Bow (“saving grace”) or the “Achilles’ Heel” of spreadsheet development.
[...] The saving grace is that the calculation can be hidden within a Named Lambda function [...] which is easier on the eye. [M5]
[...] cells whose formulas are way too long to be put in a single cell is Excel’s Achilles Heel (and a footgun that you are nearly guaranteed to encounter [...]). This LAMBDA proposal as written seems to exacerbate that problem [...]. [HN9]
To resolve these tensions, commenters proposed craft practices [38] for lambda authoring and use.
Spreadsheet research has already documented the widespread phenomenon of end-users and institutions advocating for development standards and best practices, whether explicitly borrowed from software engineering or independently reinvented. lambda is no exception, prompting discussions and suggestions about patterns and practices when authoring, naming, commenting, and applying it.
Discussions on issues of authoring lambda functions included naming conventions and problem decomposition using let bindings for subexpressions.
[Referring to a function named COMBINEλ] I added the Greek λ simply as a flag to assist me in reading the formulas [M5]
the definition of the Lambda function [...] within LET as a locally-scoped function is something I have adopted [M5]
Others proposed separating error handling and core logic:
[M36] one approach [...] about handling error would be to have Lambda in two layers [...] putting the pseudo code here,
MAIN = Lambda(n,IF(n<>int(n), "Enter integer", FIB(n))) FIB=Lambda(n,..................)
Another example is the use of partial application to deal with limited default parameter capabilities:
[M9] you could approach it like so:
Area := LAMBDA(dim_1,LAMBDA(dim_2,dim_1*dim_2))
Then partially apply the 2, you get:
=Area(2) => =LAMBDA(dim_2,2*dim_2)
In turn, each of the above proposals sparked questions about their effective use. For example:
to what extent should I use Names for a hierarchy of Lambda functions in order to modularise the code? [M5]
Editing and reading long formulas is already challenging [39]. lambda encourages an extended, programmatic style of formula writing that throws into sharp relief the limits of the current formula management environment, exposing several inadequacies of tooling and user experience for formulas.
Commenters therefore drew comparisons explicitly and implicitly to aspects of tooling well-established in the development environments of professional programmers: syntax highlighting, multi-line editing, parentheses matching, code completions and definitions, and version control.
I don’t think name manager cuts it, they’ll need a formula manager. Comments between coding lines and tooltips are going to be necessary. Sharing, vital [...] [YT1045]
Functions that were developed and shared during discussions often served a need so fundamental to some user’s work that they expressed their desire for its inclusion in the standard function library. Often this was motivated by the assumption that a library function would be more performant and comprehensible than a custom function.
Here is my upvote for the SPLIT function. I am very surprised Excel 365 did not have that as a built-in [...] [R11]
You should use native functions where you can. They are faster, more stable, and just better written codes. [...] If you ever need to share your workbook with others, they will appreciate native formula based approach over [custom functions] that they may not understand. [R85]
Commenters encountered barriers that impaired or prevented their use of lambda. We found three out of six programming learning barriers that Ko et al. observed [40]: understanding barriers, where the lambda behaviour departed from their expectations; use barriers, which stopped them authoring and applying lambda; and many instances of coordination barriers, where users could not combine lambda with other spreadsheet features, such as dynamic arrays. For example:
[...] I cannot get even a really simple LAMBDA to work using the Name Manager [...] [M37]
The slip was to use the Name [...] within its own definition [...] [M5, responding to above]
What if the LAMBDA function has two variables, then how to use these functions? [YT1985]
[...] I wasn’t aware at all that the parameter name [...] I chose was actually referring to a very distant cell name in Excel sheet. [...] [M26]
The causes of barriers ranged from misinterpretation of marketing material, to lack of familiarity with programming jargon that lambda gets it name from, to mistaken assumptions about its capabilities and intended use cases, to the differences between lambda and implementations in other programming languages as anonymous functions.
Say I have a simple LAMBDA function := LAMBDA(number, number+1). Is there a way to obtain the “number” by popping out an input box with a prompt like “give me a number”? [M14]
you can’t use LAMBDAs like VBA to perform interactions or manipulations of things outside the scope of the grid. [M9, responding to above]
By lambda I thought its something related to wavelength of a frequency. [YT1828]
To address and overcome these barriers, commenters employed a variety of strategies. Some asked for help, or searched online documentation. For example:
1. Can I save my LAMBDA to Excel so that it can be accessed in all workbooks instead of only the workbook it was created on? 2. When my LAMBDA is called up, can it display the parameters(syntax) the same way a native function does? [M35]
Others posted examples containing errors and asked others for help in fixing the error. In debugging and repairing these errors, commenters were able to get personalised and grounded explanations for aspects of lambda usage.
I defined a recursive lambda [...] but received #value. Can u help to resolve this? [M21]
Your lambda requires three parameters [...] so your reference to itself should have 3 parameters as well. [M9, responding to above]
We observed much experimentation and hypothesising. Commenters conducted systematic examinations of certain aspects of lambda usage, such as performance limitations, and interactions with other spreadsheet features, and reported their findings to the community.
I don’t know if the rest of you love lambdas as much as I do but I have been using them extensively [...] and would like to share one of the tricks I have learned. [...] [R19]
I’m trying out excels new LAMBDA function. I’m trying to call it recursively as they write in the press release that you would be able to. [...] [R48]
Often, commenters were unable to completely determine the reasons for observed behaviours, and in response developed ‘folk theories’ [41]–[43] about lambda, which, while possibly incorrect, facilitated the formation of mental models that allowed commenters to reason about the usage of lambda.
[...] If it is actually an iterative function then it is likely to have an underlying recursive function associated with it. The lack of NUM error may be telling or it may simply result from the fact that BYROWS always operates “inside LAMBDA”. The more we deal with recursive LAMBDAS the better we will understand their underpinnings. [YT1263]
[...] BYROW etc don’t seem to have the overhead that recursive functions do. They don’t return the NUM! error. I think they’ve been built using single vectors [...] They know when to stop in the same way as any other formula as they always point to a defined range or array. [...] [YT1045, responding to above]
In end-user programming, the focus is on completing the task and the program is a means to an end, whereas in end-user software engineering, the focus is on the program itself: its correctness, maintainability, and reuse [28]. Discussions of naming and reuse prompted by lambda signal a shift from the former to the latter.
lambda definitions provoke end-user consideration of naming conventions because, notwithstanding a trivial invocation, names are compulsory arguments to let and lambda. A key reason for the approachability of spreadsheet programming is the lack of a forced consideration of naming: grid references provide automatic names for variables; to instantiate a variable the user needs only enter a value or a formula – the act of choosing a grid location subsumes the act of naming. While assigning names to grid ranges is supported through the name manager, only a small fraction of spreadsheet users know of the feature, let alone use it [44]. Thus, this discussion could only have been precipitated by let and lambda.
[...] Where you’ve chosen to name your function something related to the report, I think it should be related to the action. [...] with this one and work out the best practice [...] [YT1045]
I don’t think it is Microsoft’s duty to help us name things smartly. That is our duty. It is funny. The vast majority of computer users on the planet earth do not even have the day 1, basic computer skill of naming things smartly. [...] [YT1218]
Similarly, until the introduction of lambda, users had to learn a different programming language (e.g., VBA, JavaScript) to define functions, and organizational IT teams often restrict their use over security concerns (Section 4.5). The capabilities of lambda leads to speculations about changes to “practice and mindset” required to build spreadsheets.
The future is to write robust formulas for complex and reusable tasks [...] or build even more complex ones like subroutines [...] a structural revolution [...] [YT370]
After experimenting for a while with LET and now LAMBDA [...] the change of practice and mindset required to create good [...] solutions is so great that one’s past experience [...] may itself be the greatest impediment [...] [M5]
The computational nature of lambda raised discussions regarding the identity of spreadsheet users as programmers, spreadsheets as code, and the expertise required to harness lambda. One perspective distinguished spreadsheet authoring and programming, similarly viewing lambda as a separate to coding.
That’s true if you know VB. Most Excel users don’t and this is a simple method to build complex functions without having to code. [YT421]
Many people that use Excel are office workers and don’t have enough background in programming or the time to learn it. You can pick up the LAMBDA function in a few minutes though if you are already familiar with many other Excel functions. [YT421]Prior work suggests that this perspective can be motivated by wanting to distance oneself from a “programmer” [45]. This tension of identity was also reflected in the discussion.
Whilst [...] Lambda functions are simple extensions of the traditional spreadsheet methods [...] the process of solution development shifts from the ad-hoc to being a programming exercise [...] traditional methods allow users to interact with their numbers whilst remaining in denial that they are actually programming [M5]The expertise required to use lambda was another common theme. Central to the discussion was the notion of expertise across an organization, particularly the practice of those with expertise building and sharing solutions with those who do not. Some viewed lambda as another advanced feature reserved for those with expertise.
Most organizations [...] only have a couple people who can actually make and edit the advanced sheets [...] and lots of people who use those sheets with a very, very rudimentary knowledge of Excel to generally get their jobs done. I don’t really see the addition of new advanced functionality changing that [...] [HN38]Several users expressed reluctance or concerns because collaborators might not be familiar with lambda functions; thus, lambda functions might hinder comprehension.
[...] though how might non-technical folks feel about a coworker sending them a spreadsheet with function-values? [HN4]In contrast, others indicated that lambda can improve sharing by providing a way to implement advanced functionality without resorting to traditional programming such as VBA, reaffirming that some users perceive a distinction between spreadsheets and code.
There’s always been this midpoint of complexity when making spreadsheets that coworkers will use. Including macros scares them away but using long, un-named formulas does not even though it is much less clear what it’s doing [...] a macro was not needed, only a label and some arguments to lower the cognitive load. [HN95]
Consistent with prior observations, we observed derision and gatekeeping behaviour regarding the identity and expertise of spreadsheet users as programmers [45].
What has instead happened, I shit you not, is we have “Excel influencers" teaching people recursion “without code!" (aka without VBScript). I cried and I laughed when I first saw, it was a watershed moment in CS education. [HN48]
[...] no mention of debugging. In the hands of Excel cowboys, this can become another foot gun. [HN124]
[...] The irony is that this feature will almost certainly be met with derision & scorn from the CS crowd and clueless shrugs from excel users. [HN182]
However, we also observed the championing and support for the perspective that spreadsheet users are part of a programming community.
Of course this also means that Excel becomes even more of a slippery slope towards programming generally, which can only be a good thing. [HN161]
[...] this could actually be a really natural bridge into programming for a lot of people whose advanced Excel skills already have them on the cusp. [HN119]
Debate about the identity of spreadsheet users as programmers is by no means new [45], but the introduction of a first-class computational abstraction is a fresh opportunity for users and researchers alike to revisit this discussion.
Discussions of potential alternatives to lambda, including other ways of achieving the same thing as lambda, or simply citations of other technologies, helped users situate lambda among a wider suite of tools. The most common comparison was to VBA. Users discussed other programming languages, software packages, and alternative ways of using existing spreadsheet features.
After expertise, which we have covered, the salient axes of comparison were security and performance. When contrasted with VBA macros, lambda was seen to have security and performance benefits, due to the perceived superiority of the formula calculation engine over the VBA environment.
Alternatively, Excel lambda-based udfs will be faster than VBA UDFs because the Excel Calc engine is multi-threaded, whereas VBA is single-threaded. [R21]
Lambdas also have the advantage of working in situations where macros are not allowed or on platforms where VBA is not available [...] though the latter also allows you to perform many workbook management tasks. [YT909]
The problem with “macros” is that they can be arbitrary VBA code that can invoke OS functions and foreign applications. Lambdas can only invoke Excel functions that you can invoke anyway [...] Lambdas merely add an abstraction mechanism, they otherwise don’t provide access to new functionality. [HN88]
We observed differences between the four communities studied, reflective of the differing demographics of users of these websites and their differing concerns. Together, they showcase a diverse range of stakeholder perspectives.
For example, Hacker News, a community aimed towards technology industry professionals, involved comparative and analytical comments that considered the reception and consequences of lambda on the spreadsheet community. Comments from Hacker News were the longest on average (median=47 words), in part because they explored technical concepts. Many drew comparisons with programming concepts, research that inspired lambda, potential improvements based on other programming paradigms, or whether using spreadsheets constituted programming.
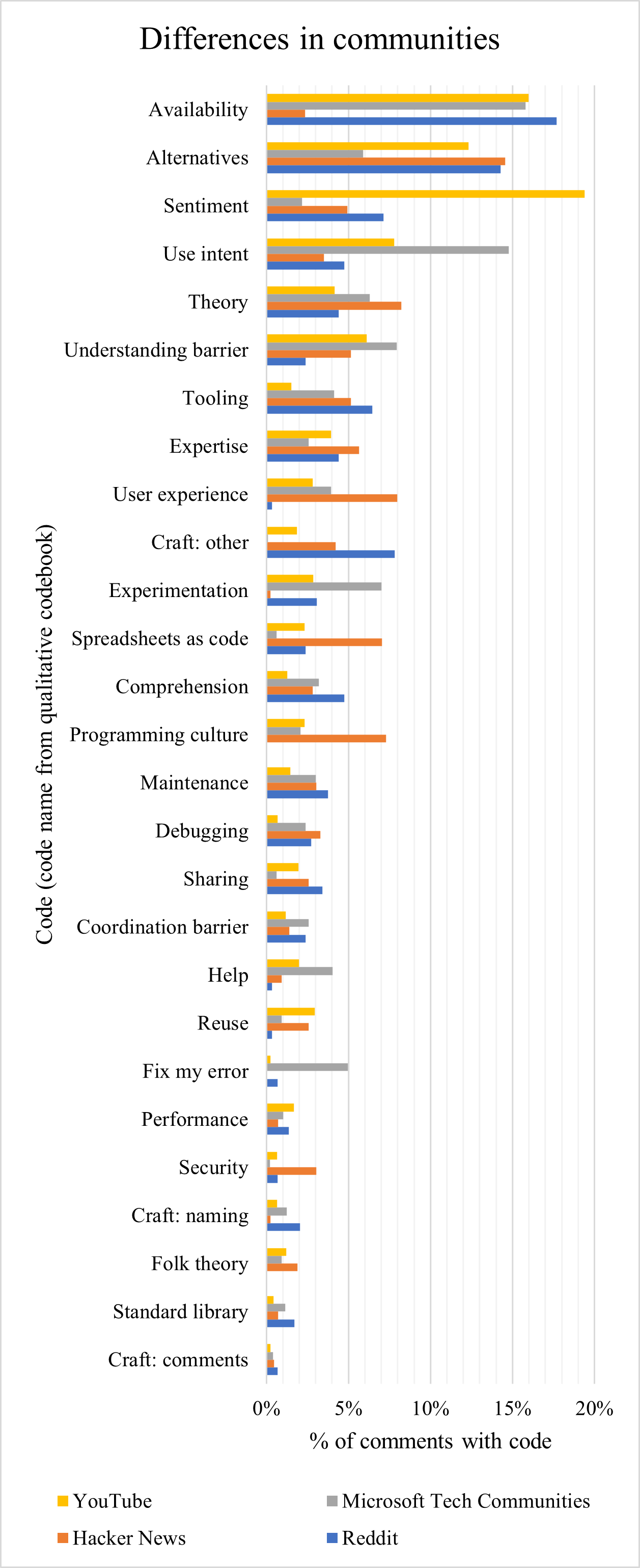
On the other hand, Microsoft Tech Community is the official discussion and help forum for Microsoft products, including Excel. Users fell largely into two groups: a small number of experts who contributed to several threads, and a large number of users who came to seek help, started a single thread, and posted only a few comments on it. Comments were somewhat long (median=44 words) and often included formulas and attached spreadsheets. This can be seen in the high occurrence of use intent and experimentation, both of which relate to users writing examples of lambda (Fig. 1).
Reddit discussions were more concerned with sharing
craft practices. Most threads came from the
r/excel forum, which is focused on sharing techniques and
news, and oriented towards practitioners and enthusiasts. Reddit
comments discussed naming and commenting, how to use
lambda to improve maintainability and comprehension, and
pitfalls to avoid. Reddit users appeared to have a wide range of
expertise. Some had formal knowledge of programming, although a smaller
proportion than Hacker News.
YouTube comments were often in response to tutorial videos, which users presumably watched to learn about lambda. Our YouTube data contained more unique users and comments than the other three sources combined, but its comments were also the shortest (median=13 words), and often not informative. YouTube comments often reflected users’ unjustified sentiment towards lambda (Fig. 1).
To illustrate the differences, we present the relative frequency of codes across different communities in Figure 1. We recognise inherent limitations in attempting to quantify qualitative codes, and present this purely as an narrative aid. We are not making quantitative claims about the representativeness of these code frequencies.
The question of whether spreadsheet users are programmers is not inconsequential terminological hair-splitting; it has implications for the role spreadsheets play in society.
Programmer is a marked identity [46] with cultural associations against which end-users judge themselves. The conceptualisation of spreadsheet use as a programming activity therefore directly suggests to users whether spreadsheets are for people ‘like them’ or for ‘others’. People’s skills are shaped and captured by software, resulting in an intimate binding of one’s professional value to the software one uses [47].
It has been previously observed that spreadsheet users do not view themselves as programmers [45]. Our findings provide additional nuance: some spreadsheet users view themselves as programmers, but others do not. Some are unaware that a distinction can be made, or if a distinction is to be made, what the appropriate grounds are. Users who concede that spreadsheet formula authoring can be viewed as programming may nonetheless not self-identify as programmers.
boyd and Ellison describe the community process of impression management [48], where the expression of self through social media becomes a mechanism for forming and signalling identity. Though highly individualised, the identity of “programmer” is at the same time a community identity, subject to community negotiation. In this respect it is similar to sociological theories of group formation [49]. Kinship, friendship, and neighbourly groups serve as means of allocating resources, but also as a psychological device for uniting the sense of self with a sense of belonging. Thus, the use and discussion of lambda can serve both as a peer-signalling mechanism as well as to enact one’s own identity as a programmer.
lambda creates new bridges (and gulfs) between programmers and ‘others’. Many commenters implied that using lambda is closer to traditional notions of programming than authoring spreadsheet formulas, but it is unclear what underpins this perception. Does managing complexity via lambda resemble software engineering practices, associated with programming and dissociated from spreadsheets? As Wing notes, decomposition and abstraction are key to computational thinking [50].
Some commenters predicted that lambda is going to change the way spreadsheets are built. However, absent better tooling and higher levels of user expertise, it is doubtful whether a lambda-centric spreadsheet development approach induces better design, testing, or documentation. While some users anticipated a “structural revolution”, such optimism ought to be tempered by the fact that formula writers constitute a minority of spreadsheet users, and corpus studies show that as few as 7% of spreadsheets contain a single formula [51], [52].
Ragavan et al.’s study of spreadsheet comprehension found two main bottlenecks to formula comprehension: first, the information-seeking detours required to understand the quantities on which a formula operates; and second, understanding the usage of unfamiliar formula functions [39].
While some commenters felt that lambda improved formula comprehension, particularly regarding ‘megaformulas’, others felt that these problems would be worsened. Ragavan et al.’s findings allow us to identify the source of this contradiction: first, the naming of subexpressions can either eliminate or necessitate information-seeking detours; and second, with lambda, there is both the potential for more intelligible, domain-specific functions as well as for arbitrary, poorly-documented constructions. The resolution of this tension cannot be (purely) in the technical design of the formula language, and thus we observed users develop craft practices in response.
lambda promotes attention investment in complex formulas, and thus raises issues of tooling. Discussions made clear the value of ideas from professional development environments, such as syntax highlighting, code definitions, autocomplete, versioning and library management, and so on. We are not the first to observe such needs or propose their implementation. However the wholesale implementation of professional features for end-user programmers is seldom an effective strategy; the design of Calculation View [44] shows how a code-like representation might be sympathetically introduced as a companion to the spreadsheet grid.
Opportunities also arise for misuse. Common anti-patterns in programming (e.g., abuse of recursion, deeply nested conditions, deep chains of invocations) may surface through lambda. Opportunities emerge for educating spreadsheet users about such misuses, and for addressing them (e.g., via refactoring tools [53]). By analogy to prior research, there are research opportunities in unit testing and documentation [28].
Analyses of online communities are subject to self-selection bias; participation in our dataset is skewed towards end-user programmers with an intrinsic interest in lambda and in developing their technical skills. This group may not be representative. On the other hand, attitudes and practices of spreadsheet use often percolate through the end-user community via influential, opinionated, and expert individuals who advocate for features and techniques [54], [55]. As such, it seems advantageous to study a group whose views are likely to influence others.
During coding, we felt limited by our unitisation of the data into individual comments. Sometimes codes were more properties of (sub-)threads than of individual comments. There were digressive and discursive comments which, despite arising in the context of one set of codes, were not directly relevant to them. We developed heuristics for consistency (e.g., to qualify for a code, a reply must add new information and not merely repeat or agree with a previous comment) but still felt the need for a more flexible scheme than applying codes to individual comments. While in this study we followed the single-comment model of previous work [33], this strikes us as an area with potential for methodological innovation.
Our data captures an early stage of the lambda release, with access limited for most of this period to a public beta testing program (albeit a very large one, with millions of members). We could have waited until lambda had been in general release for some time. However, observations of user experiences at all stages of a product lifecycle are useful; documenting early barriers and misconceptions will enable comparisons with user attitudes in the future.
We studied reactions to lambda abstractions in spreadsheets through a thematic analysis of nearly 2,700 comments posted on four online forums. Commenters noted that abstraction has both benefits and drawbacks, and that complementary practices (e.g., variable naming, documentation) and better tooling (e.g, editors, sharing and versioning tools, testing and debugging utilities) are necessary to use lambda effectively. They also anticipated challenges around comprehension by less-expert users. lambda prompted mindset changes towards investing in authoring more reusable abstractions.
The Excel lambda function reopens debate around the identity of spreadsheet users as programmers. It raises questions of whether users ought to learn a ‘traditional’ programming language to access concepts such as abstraction and recursion, and whether lambda abstractions are a smooth segue for spreadsheet users to begin learning a language such as Python. Each of these opens a rich avenue for future work.
irrelevant: not related to lambdas, or related to lambdas but not informative, or not in English
comprehension: All discussions about ability to understand/read/comprehend formulas/lambdas (or the lack), granular at the level of a single formula
debugging, testing, auditing: (abstract) The ability to debug, test, audit formulas/lambdas, their ux, challenges
maintainability: discussions about formula and spreadsheet maintainability made better or worse (includes simplification, modularity, error-proneness), only if this doesn’t fall under debugging testing and auditing. Discussions about code-quality (code being formula), importance, or lack thereof
craft practices: naming: discussion about naming of parameters, the challenges, importance, etc
craft practices: comments: discussion about the ability to add comment in formulas
craft practices: others: other craft practices; suggest some usage idiom or technique
availability: discussion about access to lambda, channels, Excel versions, various end points (e.g., desktop, web, and mobile)
sharing: sharing formulas and lambdas, the challenges; a reuse scenario where colleagues/other people are explicitly mentioned, or sharing files with lambdas / collaboration (does not include sharing files in a forum for debugging support)
reuse: reusing formulas and lambdas, across workbooks, from coworkers; mentions scenarios where lambda is used multiple times
user experience: consideration of aspects of the experience of overall current lambda usage, but not mentioning tooling keywords (e.g., current syntax, current way of writing)
tooling: explicit mention of: editor, version control, IDE, debugger, package manager, repository. A subset of user experience.
standard formula library: references to functionality that should be built in to spreadsheet formula language / functions, e.g. regex
performance: discuss speed, memory requirements, etc. for lambdas (or alternatives, in comparison)
security: discuss security issues for lambdas (or alternatives, in comparison)
understanding barriers: the process of understanding lambdas, the desire to, the challenge, common misunderstandings. Also, misreadings - perhaps assumptions based on marketing material about what lambdas are like. Includes asking questions about lambda understanding. This also includes ‘understanding’ and ‘use’ barriers as per Ko et al.’s framework.
coordination barrier: any confusion or remark about interaction between *lambdas* and some other Excel feature
sentiment: Positive / negative sentiment about lambdas with no justifications (e.g., lambdas are nice).
use intent or scenario: shares concrete current or anticipated use cases for lambdas (or a use case inspired by discussion of lambdas, even if lambdas are not the best tool to solve the problem)
sensemaking: help: use of help resources, their usefulness, or their unhelpfulness. Asking others on the internet for help on things that should be in documentation
sensemaking: experimentation: ‘I tried/will try X’, probing the behaviour and possibilities of lambda
folk theory: guessing about lambda behaviour, or why lambdas interact with other features in a certain way (without actually trying something out, or trying but not getting direct evidence for the guess). Specifically refers to an unverified guess or hypothesis about how lambdas work. Look out for sentences such as: ‘I think what is happening is X’, or ‘I guess X happens becuse Y’. An episode of understanding (non-barrier) (e.g., ‘I don’t understand why Y happens’) may culminate in folk (e.g., ‘I guess it is because of X’) if it isn’t or can’t be properly answered in the thread.
fix my error: comments that are requesting or attempting to fix a bug in a lambda
spreadsheets as code: discussion about the differences/similarities of spreadsheets and programming, whether users are programmers, “real programming”
spreadsheet expertise: consideration of skill/knowledge required to use lambdas or alternatives
programming theory: explicit mention of formal academic concepts from computer science or programming theory such as types, currying, recursion
programming culture: references to programming culture, or concepts adjacent to programming, such as project-euler, XKCD, scheme, lisp interpreter, or tracing lineage of functional programming ideas (overlaps with alternatives, if they mention concrete implementations)
alternatives: discussions of potential alternatives to LAMBDA (including other ways of doing the same thing as lambda), or comparison/citation of other technologies (thus helping situate Lambda among wider suite of tools)
We thank the reviewers for their careful feedback.